递归函数
在一个函数中再次调用该函数自身的行为叫做递归,这样的函数被称作递归函数。
例如,想要编写一个阶乘的函数int fact(int n),使用循环来实现是完全可以的。但是根据阶乘的递推式n!=n×(n-1)!,我们可以写成如下形式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| #include <iostream>
#include <cstdio>
using namespace std;
int fact(int n)
{
if (!n)
return 1;
else
return n * fact(n - 1);
}
int main()
{
int n;
scanf("%d", &n);
printf("%d\n", fact(n));
return 0;
}
|
在编写一个递归函数时,函数的停止条件是必须存在的。在刚刚的例子中,当n=0时fact并不是继续调用自身,而是直接返回1。
如果没有这一条件存在,函数就会无限地递归下去,程序就会失控崩溃了。
栈
栈(Stack)是支持push和pop两种操作的数据结构。push是在栈的顶端放入一组数据的操作。反之,pop是从其顶端取出一组数据的操作。因此,最后进入栈的一组数据可以最先被取出(这种行为被叫做LIFO:Last In First Out,即后进先出)。
通过使用数组或者链表等结构可以很容易实现栈,同时,在C++标准库中,有相应的STL容器去完成该操作。
函数调用的过程是通过使用栈实现的。因此,递归函数的递归过程也可以改用栈上的操作来实现。
以下是使用stack的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| #include <stack>
#include <cstdio>
using namespace std;
int main()
{
stack<int> s;
s.push(1);
printf("%d\n", s.size());
if (s.empty())
printf("栈为空\n");
else
printf("栈不为空\n");
printf("%d\n", s.top());
s.push(2);
s.push(3);
s.pop();
s.pop();
s.pop();
return 0;
}
|
队列
队列(Queue)与栈一样支持push和pop两个操作。但与栈不同的是,pop完成的不是去除最顶端的元素,而是取出最底端的元素。也就是说最初放入的元素能够最先被取出(这种行为被叫做FIFO:First In First Out,即先进先出)。
如同栈一样,队列也预先设置了相应的STL容器去实现这些操作。
以下是使用queue的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| #include <queue>
#include <cstdio>
using namespace std;
int main()
{
queue<int> s;
s.push(1);
printf("%d\n", s.size());
if (s.empty())
printf("队列为空\n");
else
printf("队列不为空\n");
printf("%d\n", s.front());
s.push(2);
s.push(3);
s.pop();
s.pop();
s.pop();
return 0;
}
|
深度优先搜索
深度优先搜索(DFS,Depth-First Search)是搜索的手段之一。它从某个状态开始,不断地转移状态直到无法转移,然后回退到前一步的状态,继续转移到其他状态,如此不断重复,直至找到最终的解。例如求解数独,首先在某个格子内填入适当的数字,然后再继续在下一个格子内填入数字,如此继续下去。如果发现某个格子无解了,就放弃前一个格子上选择的数字,改用其他可行的数字。根据深度优先搜索的特点,采用递归函数实现比较简单。
深度优先搜索从最开始的状态出发,遍历所有可以到达的状态。由此可以对所有的状态进行操作,或者列举出所有的状态。
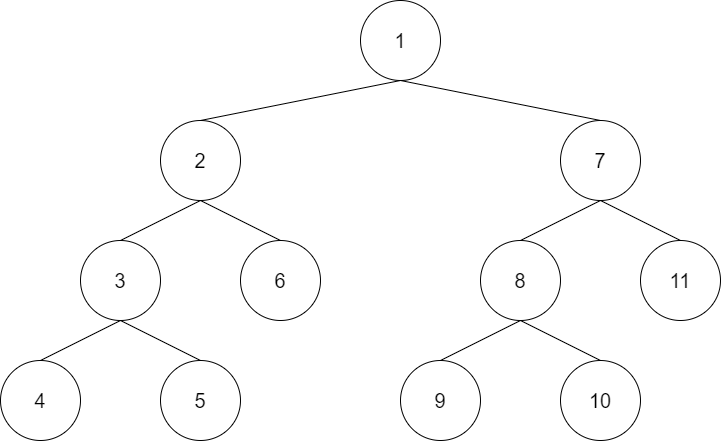
部分和问题
测评链接
部分和问题
题目描述
给定整数a1、a2、…、an,判断是否可以从中选出若干数,使它们的和恰好为k。
输入格式
第一行有两个整数n和k,分别表示数字的个数。
第二行有n个整数,表示给出的n个整数ai。
输出格式
Yes或No
输入输出样例
输入 #1
输出 #1
输入 #2
输出 #2
限制条件
1 ≤ n ≤ 20
-108 ≤ ai ≤ 108
-108 ≤ k ≤ 108
题解
从a1开始按顺序决定每个数加或不加,在全部n个数都决定后再判断它们的和是不是k即可。因为状态数是2n+1,所以复杂度是O(2n)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| #include <iostream>
#include <cstdio>
using namespace std;
const int N = 1e5 + 7;
int n, k;
int a[N];
bool dfs(int i, int sum)
{
if (i == n)
return sum == k;
if (dfs(i + 1, sum + a[i]))
return true;
if (dfs(i + 1, sum))
return true;
return false;
}
int main()
{
scanf("%d%d", &n, &k);
for (int i = 0; i < n; i++)
scanf("%d", &a[i]);
if (dfs(0, 0))
printf("Yes\n");
else
printf("No\n");
return 0;
}
|
广度优先搜索
广度优先搜索(BFS,Breadth-First Search)也是搜索的手段之一。它与深度优先搜索类似,从某个状态出发探索所有可以到达的状态。
与深度优先搜索的不同之处在于搜索的顺序,广度优先搜索总是先搜索距离初始状态近的状态。也就是说,它是按照开始状态->只需1次转移就可以到达的所有状态->只需2次转移就可以到达的所有状态->……这样的顺序进行搜索。
对于同一个状态,广度优先搜索只经过一次,因此复杂度O(状态数×转移的方式)。
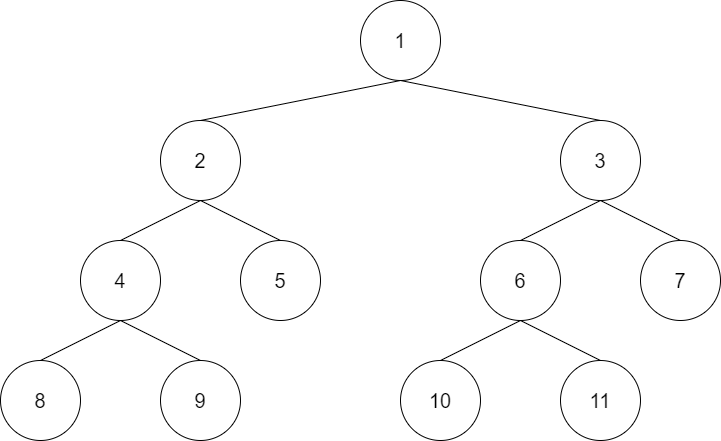
深度优先搜索(隐式地)利用了栈进行计算,而广度优先搜索则利用了队列。搜索时首先将初始状态添加到队列里,此后从队列的最前端不断取出状态,把从该状态可以转移到的状态中尚未访问过的部分加入队列,如此往复,直至队列被取空或找到了问题的解。通过观察这个队列,我们就可以知道所有的状态都是按照距初始状态由近及远的顺序遍历的。
迷宫最短路径
测评链接
迷宫的最短路径
题目描述
给定一个大小为N×M的迷宫。迷宫由通道和墙壁组成,每一步可以向邻接的上下左右四格的通道移动。
请求出从起点到终点所需的最小步数。
本题假定从起点一定可以移动到终点。
输入格式
第一行有两个整数N和M,分别表示迷宫的行数和列数。
接下来N行,每行M个字符,#表示墙壁,.表示通道,S表示起点,G表示终点。
输出格式
一个整数表示从起点到终点所需的最小步数。
输入输出样例
输入 #1
1
2
3
4
5
6
7
8
9
10
11
| 10 10
#S######.#
......#..#
.#.##.##.#
.#........
##.##.####
....#....#
.#######.#
....#.....
.####.###.
....#...G#
|
输出 #1
限制条件
题解
广度优先搜索按照距开始状态由近及远的顺序进行搜索,因此可以很容易地用来求最短路径、最少操作之类问题的答案。这个问题中,状态仅仅是目前所在位置的坐标,因此可以构造成pair或者编码成int来表达状态。转移的方式为四方向移动,状态数与迷宫大小是相等的,所以时间复杂度是O(4×N×M)=O(N×M)。
在广度优先搜索中,只要将已经访问过的状态用标记管理起来,就可以很好地做到由近及远的搜索。这个问题中由于要求最短距离,因此使用d[N][M]数组把最短距离保存起来。初始距离全部都是0,这样只需特别判定起点,即可分辨出到达的位置和未到达的位置,气到了标记作用。
因为要向4个不同方向移动,用二维数组dir[4][2]表示四个方向向量,通过循环就可以实现四个方向移动的遍历。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
| #include <iostream>
#include <cstdio>
#include <utility>
#include <queue>
using namespace std;
typedef pair <int, int> P;
const int MAXN = 105;
int N, M;
int sx, sy;
int d[MAXN][MAXN];
char maze[MAXN][MAXN];
int dir[4][2] = { {0,-1},{-1,0},{0,1},{1,0} };
queue <P> q;
int main()
{
scanf("%d%d", &N, &M);
for (int i = 1; i <= N; i++)
for (int j = 1; j <= M; j++)
{
cin >> maze[i][j];
if (maze[i][j] == 'S')
{
sx = i;
sy = j;
}
}
q.push(make_pair(sx, sy));
while (q.size())
{
int x = q.front().first, y = q.front().second;
if (maze[x + dir[0][0]][y + dir[0][1]] == 'G')
{
printf("%d\n", d[x][y] + 1);
break;
}
else if (maze[x + dir[0][0]][y + dir[0][1]] == '.' && d[x + dir[0][0]][y + dir[0][1]] == 0)
{
q.push(make_pair(x + dir[0][0], y + dir[0][1]));
d[x + dir[0][0]][y + dir[0][1]] = d[x][y] + 1;
}
if (maze[x + dir[1][0]][y + dir[1][1]] == 'G')
{
printf("%d\n", d[x][y] + 1);
break;
}
else if (maze[x + dir[1][0]][y + dir[1][1]] == '.' && d[x + dir[1][0]][y + dir[1][1]] == 0)
{
q.push(make_pair(x + dir[1][0], y + dir[1][1]));
d[x + dir[1][0]][y + dir[1][1]] = d[x][y] + 1;
}
if (maze[x + dir[2][0]][y + dir[2][1]] == 'G')
{
printf("%d\n", d[x][y] + 1);
break;
}
else if (maze[x + dir[2][0]][y + dir[2][1]] == '.' && d[x + dir[2][0]][y + dir[2][1]] == 0)
{
q.push(make_pair(x + dir[2][0], y + dir[2][1]));
d[x + dir[2][0]][y + dir[2][1]] = d[x][y] + 1;
}
if (maze[x + dir[3][0]][y + dir[3][1]] == 'G')
{
printf("%d\n", d[x][y] + 1);
break;
}
else if (maze[x + dir[3][0]][y + dir[3][1]] == '.' && d[x + dir[3][0]][y + dir[3][1]] == 0)
{
q.push(make_pair(x + dir[3][0], y + dir[3][1]));
d[x + dir[3][0]][y + dir[3][1]] = d[x][y] + 1;
}
q.pop();
}
return 0;
}
|
深度优先搜索与广度优先搜索比较
二者都会生成所有能够遍历到的状态,因此需要对所有的状态进行处理时二者都是可行的。但是递归函数可以很简短地编写,而且状态的管理也更简单,所以大多数情况下还是用深度优先搜索实现。反之,在求取最短路径时深度优先搜索需要反复经过同样的状态,所以此时还是使用广度优先搜索为好。
广度优先搜索会把状态逐个假如队列,因此通常需要与状态数成正比的内存空间。反之,深度优先搜索是与最大的递归深度成正比的。一般与状态数相比,递归的深度并不会太大,所以可以认为深度优先搜索更加节省内存。
剪枝
顾名思义,穷竭搜索会把所有可能的解全都检查一遍,当解空间非常大时,复杂度也会相应变大。比如n个元素进行排列时状态数共有n!个,时间复杂度也就成了O(n!)。这样的话,即使n=15计算也很难较早终止。这里简单介绍一下此类情形要如何进行优化。
深度优先搜索时,有时早已明确地知道从当前状态无论如何转移都不会存在解。这种情况下,不再继续搜索而是直接跳过,这一方法被称作剪枝。
 微信
微信 支付宝
支付宝





