数据库基础
SQL语言基础
SQL的概述
SQL全称:Structured Query Language,是结构化查询语言,用于访问和处理数据库的标准的计算机语言。
SQL的特点
- 具有综合统一性,不同数据库的支持的
SQL稍有不同。 - 非过程化语言(不需要关系内部的操作过程)。
- 语言简洁,用户容易接受。
- 以一种语法结构提供两种使用方式(和其他语言可以混用)。
语法特点
SQL对关键字的大小写不敏感。SQL语句可以以单行或者多行书写,以分号结束。
注释
基本格式:
1 | -- 单行注释,-- 后面一定要加一个空格 |
数据库系统简介
SQL和数据库管理系统的关系
SQL是一种用于操作数据库的语言,SQL适用于所有关系型数据库。MySQL、Oracle、SQLServer是一个数据库软件,这些数据库软件支持标准SQL,也就是通过SQL可以使用这些软件,不过每一个数据库系统会在标准SQL的基础上扩展自己的SQL语法。- 大部分的
NoSQL数据库有自己的操作语言,对SQL支持的并不好。
关系型数据库管理系统组成
数据库管理系统(DBMS)主要由数据库和表组成,一个系统可以有很多数据库,每个数据库可以有很多表。
MySQL简介
MySQL的特点
- MySQL数据库是使用
C/C++语言编写的,以保证源码的可移植性。 - 支持多个操作系统。
- 支持多线程,可以充分利用CPU资源。
- 为多种编程语言提供
API,包括C语言,Java,PHP,Python语言等。 MySQL优化了算法,有效提高了查询速度。MySQL开放了源代码且无版权制约,自主性强,使用成本低。MySQL历史悠久、社区及用户非常活跃,遇到问题,可以很快获取到帮助。
DDL
DDL解释
DDL(Data Definition Language),数据定义语言,该语言部分包括以下内容。
- 对数据库的常用操作
- 对表结构的常用操作
- 修改表结构
对数据库的操作
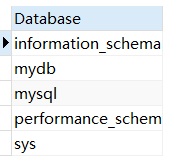
查询所有的数据库
基本格式:
1 | SHOW DATABASES; |
结果展示:

查询当前数据库
基本格式:
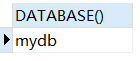
1 | SELECT DATABASE(); |
例:使用数据库mydb,查询当前所在数据库。
1 | USE mydb; |
结果展示:
创建数据库
基本格式:
1 | CREATE DATABASE [ IF NOT EXISTS ] 数据库名字 [ DEFAULT CHARSET 字符集 ] [ COLLATE 排序规则 ]; |
if not exists将会判断是否存在该数据库,如果存在,则会取消创建,这个可加可不加,如果不加的话出现重复创建的情况会报错。
例:创建数据库mydb,并输出所有数据库。
1 | CREATE DATABASE mydb; |
结果展示:
不使用if not exists创建重复数据库
1 | CREATE DATABASE mydb; |
结果展示:
1 | CREATE DATABASE mydb |
使用if not exists创建重复数据库
1 | CREATE DATABASE |
结果展示:
选择数据库
选择使用哪一个数据库,从而对其进行操作。
基本格式:
1 | USE 数据库名; |
结果展示:
1 | USE mydb |
删除数据库
基本格式:
1 | DROP DATABASE [ IF EXISTS ] 数据库名; |
if exists将会判断是否存在该数据库,如果存在,则会删除,不存在则取消执行。这个可加可不加,如果不加的话出现重复删除的情况会报错。
例:删除数据库mydb,并输出所有数据库。
1 | DROP DATABASE mydb; |
结果展示:
不使用if exists删除不存在数据库
1 | CREATE DATABASE mydb; |
结果展示:
1 | CREATE DATABASE mydb; |
使用if exists删除不存在数据库
1 | DROP DATABASE |
结果展示:
修改数据库编码
可以用来修改数据库的编码格式。
基本格式:
1 | ALTER DATABASE 数据库名 CHARACTER |
结果展示:
1 | ALTER DATABASE mydb CHARACTER |
数据类型
数据类型是指在创建表的时候为表中字段指定数据类型,只有数据符合类型要求才能存储起来,使用数据类型的原则是:够用就行,尽量使用取值范围小的,而不用大的,这样可以节省更多存储空间。
数值类型
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1byte | (-128, 127) | (0, 255) | 小整数值 |
| SMALLINT | 2bytes | (-32768, 32767) | (0, 65535) | 大整数值 |
| MEDIUMINT | 3bytes | (-8388608, 8388607) | (0, 16777215) | 大整数值 |
| INT或INTEGER | 4bytes | (-2147483648, 2147483647) | (0, 4294967295) | 大整数值 |
| BIGINT | 8bytes | (-9223372036854775808, 9223372036854775807) | (0, 18446744073709551615) | 极大整数值 |
| FLOAT | 4bytes | (-3.402823466E+38, 3.402823466351E+38) | (1.175494351E-38, 3.402823466E+38) | 单精度浮点数值 |
| DOUBLE | 8bytes | (-1.7976931348623157E+308, 1.7976931348623157E+308) | (2.2251738585072014E-308, 1.7976931348623157E+308) | 双精度浮点数值 |
| DECIMAL | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255bytes | 定长字符串 |
| VARCHAR | 0-65535bytes | 变长字符串 |
| TINYBLOB | 0-255bytes | 不超过255个字符的二进制字符串 |
| TINYTEXT | 0-255bytes | 短文本字符串 |
| BLOB | 0-65535bytes | 二进制形式的长文本数据 |
| TEXT | 0-65535bytes | 长文本数据 |
| MEDIUMBLOB | 0-16777215bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16777215bytes | 中等长度文本数据 |
| LONGBLOB | 0-4294967295bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4294967295bytes | 极大文本数据 |
日期类型
| 类型 | 大小(bytes) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
对表结构的常用操作
创建表
基本格式:
1 | CREATE TABLE [ IF NOT EXISTS ] 表名 ( |
创建表是构建一张空表,指定这个表的名字,这个表有几列,每一列叫什么名字,以及每一列存储的数据类型。
例:在数据库mydb中创建一个学生信息表student,存储学生的基本信息。
1 | USE mydb; |
结果展示:

查看表
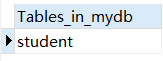
查看当前数据库的所有表名称。
基本格式:
1 | SHOW TABLES; |
结果展示:
查看创建语句
查看指定表的创建语句。
基本格式:
1 | SHOW CREATE TABLE 表名; |
例:查看表student的创建语句。
1 | SHOW CREATE TABLE student; |
结果展示:
1 | CREATE TABLE `student` ( |
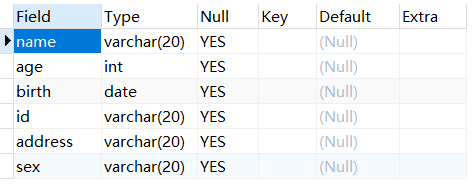
查看表结构
基本格式:
1 | DESC 表名; |
例:查看表student的结构。
1 | DESC student; |
结果展示:
删除表
基本格式:
1 | DROP TABLE 表名; |
例:删除表student的结构。
1 | DROP TABLE student; |
结果展示:
1 | DROP TABLE student |
修改表结构
添加列
基本格式:
1 | ALTER TABLE 表名 ADD 字段名 类型 (长度) [ COMMENT 注释 ] [约束]; |
例:为student表添加一个新列class。
1 | USE mydb; |
结果展示:
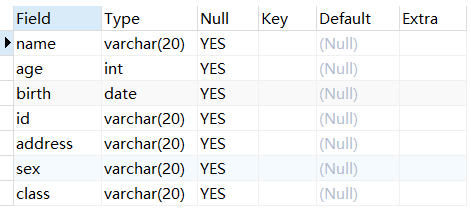
修改数据类型
基本格式:
1 | ALTER TABLE 表名 MODIFY 字段名 新数据类型 (长度); |
例:将student表中的id的数据类型修改为INT。
1 | USE mydb; |
结果展示:
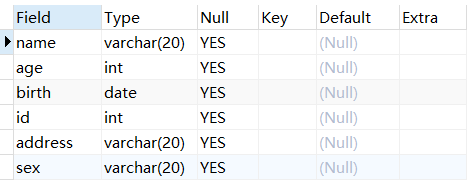
修改字段名和字段类型
基本格式:
1 | ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型 (长度) [ COMMENT 注释 ] [约束]; |
例:将student表中的class修改成score。
1 | USE mydb; |
结果展示:
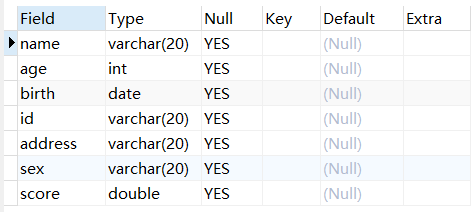
删除列
基本格式:
1 | ALTER TABLE 表名 DROP 列名; |
例:删除student表中的score列。
1 | USE mydb; |
结果展示:
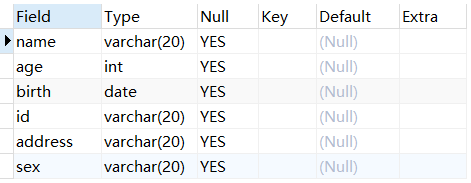
修改表名
基本格式:
1 | RENAME TABLE 表名 TO 新表名 |
例:将student表名改为stu。
1 | USE mydb; |
结果展示:
DML
DML解释
DML是指数据操作语言,英文全称是Data Manipulation Language,用来对数据库中表的数据记录进行更新。
关键字:
- 插入
INSERT - 删除
DELETE - 更新
UPDATE
数据插入
注意点:
- 插入数据时,指定的字段顺序需要与值的顺序是一一对应的。
- 字符串和日期型数据应该包含在引号中。
- 插入的数据大小,应该在字段的规定范围内。
给指定字段添加数据
基本格式:
1 | INSERT INTO 表名 (字段名 1, 字段名 2,...) |
例:向表stu中添加一条信息。
1 | USE mydb; |
结果展示:

给全部字段添加数据
基本格式:
1 | INSERT INTO 表名 |
例:向表stu中添加一条信息。
1 | USE mydb; |
结果展示:
批量添加数据
基本格式:
1 | INSERT INTO 表名 (字段名 1, 字段名 2,...) |
1 | INSERT INTO 表名 |
例:向stu表添加多条数据。
例:向表stu中添加一条信息。
1 | USE mydb; |
结果展示:

修改数据
基本格式:
1 | UPDATE 表名 |
注:修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表的所有数据。
例:将stu表中id为203428040119的人的姓名更改为比格沃斯,住址更改为旅顺。
1 | USE mydb; |
结果展示:

例:将stu表中所有人的age改为19。
1 | USE mydb; |
结果展示:

删除数据
基本格式:
1 | DELETE |
注:DELETE语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。DELETE语句不能删除某一个字段的值(可以使用UPDATE)。
例:将stu表中id为203428040119的人删除。
1 | USE mydb; |
结果展示:

例:将stu表中的所有数据删除。
1 | USE mydb; |
结果展示:

DQL
DQL解释
DQL英文全称是Data Query Language(数据查询语言),数据查询语言,用来查询数据库中表的记录。
关键字:
- 查询:
SELECT
基本查询
基本格式:
1 | SELECT |
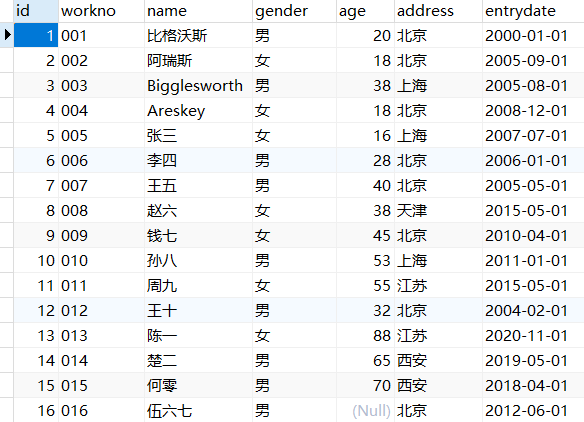
首先需要准备一个表用于接下来的数据查询,这里创建了一个员工表emp。
1 | USE mydb; |
向该表中导入数据。
1 | USE mydb; |
结果展示:
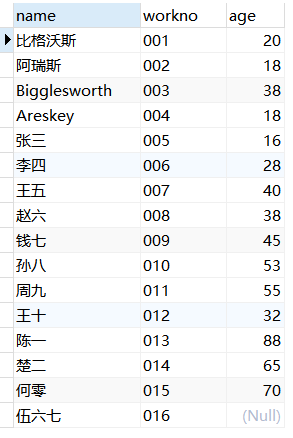
查询多个字段
基本格式:
1 | SELECT |
例:查询emp表中的字段name,workno,age。
1 | USE mydb; |
结果展示:
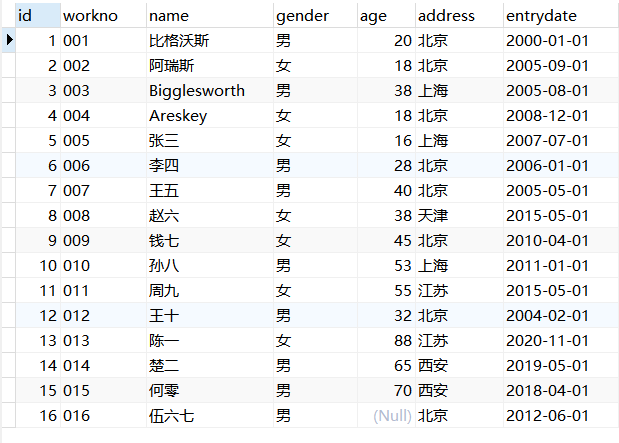
1 | SELECT |
例:查询emp表中的所有字段。
1 | USE mydb; |
结果展示:
设置别名
基本格式:
1 | SELECT |
注:AS可以省略。
例:查询emp表中的address并取名为工作地址。
1 | USE mydb; |
结果展示:
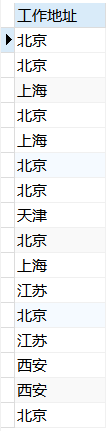
去除重复记录
基本格式:
1 | SELECT DISTINCT |
例:查询emp表中的address并取名为工作地址,并去除重复。
1 | USE mydb; |
结果展示:

条件查询
比较运算符
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <>或!= | 不等于 |
| BETWEEN … AND … | 在某个范围之内(含最小、最大值) |
| IN(…) | 在in之后的列表中的值,多选一 |
| LIKE 占位符 | 模糊匹配(_匹配单个字符,%匹配任意字符) |
| IS NULL | 是NULL |
逻辑运算符
| 逻辑运算符 | 功能 |
|---|---|
| AND 或 && | 并且(多个条件同时成立) |
| OR 或 || | 或者(多个条件任意一个成立) |
| NOT 或 ! | 非,不是 |
查询
基本格式:
1 | SELECT |
例:查询emp表中所有年龄大于等于20且小于30的员工。
1 | USE mydb; |
结果展示:

例:查询emp表中所有年龄为NULL的员工。
1 | USE mydb; |
结果展示:

例:查询emp表中年龄等于18或20或40的员工信息。
1 | USE mydb; |
结果展示:
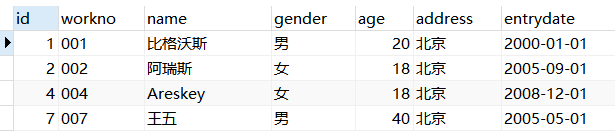
例:查询emp表中姓名为两个字的员工信息。
1 | USE mydb; |
结果展示:
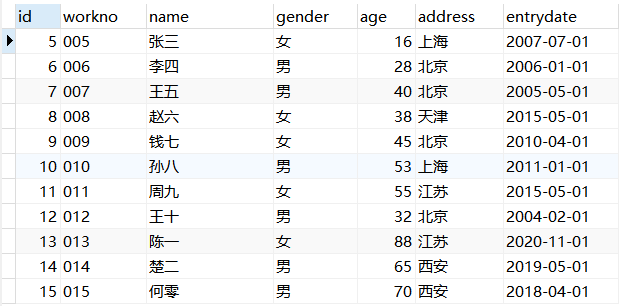
聚合函数
介绍
将一列数据作为一个整体,进行纵向计算。
常见聚合函数
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
聚合函数的使用
基本格式:
1 | SELECT |
注意点:NULL值不参与所有聚合函数运算。
count函数
例:统计该企业员工数量。
1 | USE mydb; |
结果展示:
1 | 16 |
例:统计该企业拥有年龄的员工数量。
1 | USE mydb; |
1 | 15 |
avg函数
例:统计该企业员工的平均年龄。
1 | USE mydb; |
结果展示:
1 | 41.6000 |
max函数
例:统计该企业员工的最大年龄。
1 | USE mydb; |
结果展示:
1 | 88 |
min函数
例:统计该企业员工的最大年龄。
1 | USE mydb; |
结果展示:
1 | 16 |
sum函数
例:统计该企业西安地区员工的最大年龄之和。
1 | USE mydb; |
结果展示:
1 | 135 |
分组查询
基本格式:
1 | SELECT |
WHERE与HAVING的区别:
- 执行时机不同:
WHERE是分组之前进行过滤,不满足WHERE条件,不参与分组;而HAVING是分组之后对结果进行过滤。 - 判断条件不同:
WHERE不能对聚合函数进行判断,而HAVING可以。
例:根据性别分组,统计男性员工和女性员工的数量。
1 | USE mydb; |
结果展示:

例:查询年龄小于45岁的员工,并根据工作地址分组,获取员工数量大于等于3的工作地址。
1 | USE mydb; |
结果展示:
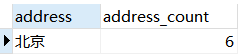
注意点:
- 执行顺序:
WHERE>聚合函数>HAVING。 - 分组之后,查询的字段一般为聚合函数的分组字段,查询其他字段。
排序查询
基本格式:
1 | SELECT |
排序方式:
ASC:升序(默认值)DESC:降序
注:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序。
例:根据年龄对公司的员工进行升序排序,年龄相同,再按照入职时间进行降序排序。
1 | USE mydb; |
结果展示:
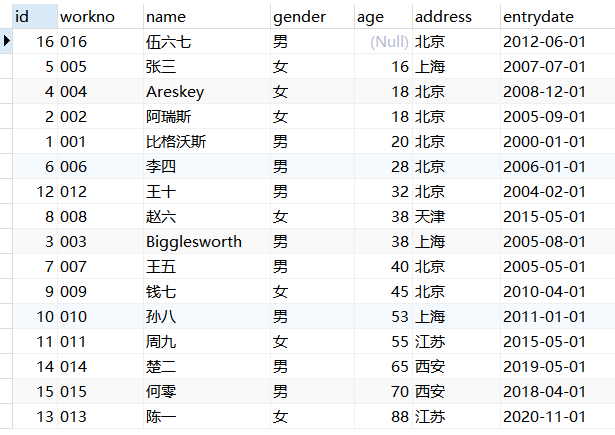
分页查询
基本格式:
1 | SELECT |
注意点:
- 其实索引从
0开始,起始索引 = (查询页码 - 1) * 每页显示记录数。 - 分页查询是数据库的方言,不同的数据库有不同的实现,
MySQL中是LIMIT。 - 如果查询的是第一页数据,起始索引可以省略,直接简写为
LIMIT 10。
例:查询第2页员工数据,每页展示`15条数据。
1 | USE mydb; |
结果展示:
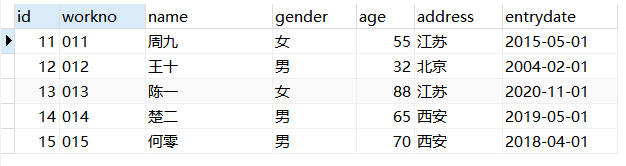
DQL执行顺序
编写顺序:
1 | SELECT |
执行顺序:
1 | FROM |
DCL
DCL解释
DCL英文全称是Data Control Language(数据控制语言),用来管理数据库用户、控制数据库用户、控制数据库的访问权限。
用户管理
查询用户
基本格式:
1 | USE mysql; |
结果展示:

创建用户
基本格式:
1 | CREATE USER '用户名' @'主机名' IDENTIFIED BY '密码'; |
例:创建用户Bigglesworth,只能够在当前主机localhost访问,密码为123456。
1 | USE mysql; |
结果展示:

例:创建用户Areskey,只能够在任意主机访问,密码为123456。
1 | USE mysql; |
结果展示:

修改用户密码
基本格式:
1 | ALTER USER '用户名' @'主机名' IDENTIFIED WITH mysql_native_password BY '新密码'; |
例:将用户Bigglesworth的密码修改为1234。
1 | USE mysql; |
结果展示:
1 | ALTER USER 'Bigglesworth' @'localhost' IDENTIFIED WITH mysql_native_password BY '1234' |
删除用户
基本格式:
1 | DROP USER '用户名' @'主机名'; |
例:删除Bigglesworth和Areskey。
1 | USE mysql; |
结果展示:
权限控制
查询权限
基本格式:
1 | SHOW GRANTS FOR '用户名' @'主机名'; |
结果展示:
1 | GRANT USAGE ON *.* TO `Areskey`@`%` |
授予权限
基本格式:
1 | GRANT 权限列表 ON 数据库名.表名 TO '用户名' @'主机名'; |
例:给用户Areskey增加mydb数据库的所有权限。
1 | USE mysql; |
结果展示:
1 | GRANT USAGE ON *.* TO `Areskey`@`%` |
撤销权限
基本格式:
1 | REVOKE 权限列表 ON 数据库名.表名 |
例:撤销用户Areskey对mydb的所有权限。
1 | USE mysql; |
结果展示:
1 | GRANT USAGE ON *.* TO `Areskey`@`%` |
注注意点:
- 多个权限之间,使用逗号分隔。
- 授权时,数据库名和表名可以使用
*进行通配,代表所有。
函数
是指一段可以直接被另一段程序调用的程序或代码。
字符串函数
常见字符串函数
| 函数 | 功能 |
|---|---|
| CONCAT(S1,S2,…Sn) | 字符串拼接,将S1,S2,…Sn拼接成一个字符串 |
| LOWER(str) | 将字符串str全部转为小写 |
| UPPER(str) | 将字符串str全部转为大写 |
| LPAD(str,n,pad) | 左填充,用字符串pad对str的左边进行填充,达到n个字符串长度 |
| RPAD(str,n,pad) | 右填充,用字符串pad对str的右边进行填充,达到n个字符串长度 |
| TRIM(str) | 去掉字符串头部和尾部的空格 |
| SUBSTRING(str,start,len) | 返回字符串str从start位置起的len个长度的字符串 |
基本格式:
1 | SELECT 函数(参数); |
字符串拼接
例:对Hello和World!进行字符串拼接。
1 | SELECT concat('Hello ', 'World!'); |
结果展示:
1 | Hello World! |
变换大写
例:将Hello World!转换为全大写。
1 | SELECT upper('Hello World!'); |
结果展示:
1 | HELLO WORLD! |
变换小写
例:将Hello World!转换为全小写。
1 | SELECT lower('Hello World!'); |
结果展示:
1 | hello world! |
左填充
例:对01进行左填充,用-填充为5个字符。
1 | SELECT lpad( '01', 5, '-' ); |
结果展示:
1 | ---01 |
右填充
例:将Hello World!转换为全大写。
1 | SELECT rpad( '01', 5, '-' ); |
结果展示:
1 | ---01 |
去除两端空格
例:将一个字符串两端的空格去除。
1 | SELECT trim(' Hello World! '); |
结果展示:
1 | Hello World! |
截取字符串
注:从1开始索引。
例:截取Hello World!的World!。
1 | SELECT substring( 'Hello World!', 7, 6 ); |
结果展示:
1 | World! |
数值函数
常见字符串函数
| 函数 | 功能 |
|---|---|
| CEIL(x) | 向上取整 |
| FLOOR(x) | 向下取整 |
| MOD(x,y) | 返回x/y的模 |
| RAND() | 返回0~1内的随机数 |
| ROUND() | 求参数x的四舍五入值,保留y位小数 |
向上取整
例:对1.1进行向上取整。
1 | SELECT ceil( 1.1 ); |
结果展示:
1 | 2 |
向下取整
例:对1.9进行向下取整。
1 | SELECT floor( 1.9 ); |
结果展示:
1 | 1 |
取模
例:求5%3。
1 | SELECT mod( 5, 3 ); |
结果展示:
1 | 2 |
随机数
例:获取一个随机数。
1 | SELECT rand(); |
结果展示:
1 | 0.49200135422125585 |
四舍五入
例:对一个随机生成的随机数进行四舍五入,保留3位小数。
1 | SELECT round( rand(), 3 ); |
结果展示:
1 | 0.893 |
日期函数
常见字符串函数
| 函数 | 功能 |
|---|---|
| CURDATE() | 返回当前日期 |
| CURTIME() | 返回当前时间 |
| NOW() | 返回当前日期 |
| YEAR(date) | 获取指定date的年份 |
| MONTH(date) | 获取指定date的月份 |
| DAY(date) | 获取指定date的日期 |
| DATE_ADD(date, INTERVAL expr type) | 返回一个日期/时间值加上一个时间间隔expr后的时间值 |
| DATEDIFF(date1, date2) | 返回起始时间date1和结束时间date2之间的天数 |
返回当前日期
例:获取当前日期。
1 | SELECT curdate(); |
结果展示:
1 | 2022-11-16 |
返回当前时间
例:获取当前时间。
1 | SELECT curtime(); |
结果展示:
1 | 20:21:37 |
返回当前日期和时间
例:获取当前日期和时间。
1 | SELECT now(); |
结果展示:
1 | 2022-11-16 20:23:53 |
分别返回当前日期
例:分别获取当前年份,月份和日期。
1 | SELECT YEAR(now()), MONTH(now()), DAY(now()); |
结果展示:

叠加日期
例:在当前的日期上增加70天。
1 | SELECT date_add( now(), INTERVAL 70 DAY ); |
结果展示:
1 | 2023-01-26 09:07:30 |
两个日期差值
例:计算当前日期和2002-09-05相差的日期。
1 | SELECT datediff ( now(), '2002-09-05' ); |
结果展示:
1 | 7378 |
流程函数
常见流程函数
| 函数 | 功能 |
|---|---|
| IF(value, t, f) | 如果value为true,则返回t,否则返回f |
| IFNULL(value1, value2) | 如果value1不为空,返回value1,否则返回value2 |
| CASE WHEN [ val1 ] THEN [ res1 ] … ELSE [ default ] END | 如果value1为true,返回res1, …否则返回default默认值 |
| CASE [ expr ] WHEN [ val1 ] THEN [ res1 ] … ELSE [ default ] END | 如果expr的值等于val1, …否则返回default默认值 |
约束
概述
- 概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据。
- 目的:保证数据库中数据的正确、有效性和完整性。
- 分类:
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段的数据不能为null |
NOT NULL |
| 唯一约束 | 保证该字段的所有数据都是唯一、不重复的 | UNIQUE |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | PRIMARY KEY |
| 默认约束 | 保存数据时,如果未指定该字段的值,则采用默认值 | DEFAULT |
| 检查约束 | 保证字段值满足某一条件 | CHECK |
| 外键约束 | 用来让两张表的数据之间建立连接,保证数据的一致性和完整性 | FOREIGN KEY |
注:约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束。
实例
例:创建一个users,其结构如下:
| 字段名 | 字段含义 | 字段类型 | 约束条件 |
|---|---|---|---|
| id | ID唯一标识 |
int | 主键,并且自动增长 |
| name | 姓名 | varchar(10) | 不为空,并且唯一 |
| age | 年龄 | int | 大于0,并且小于等于120 |
| status | 状态 | char(1) | 如果没有指定该值,默认为1 |
| gender | 性别 | char(1) | 不为空 |
1 | USE mydb; |
结果展示:

外键约束
创建外键
外键用来让两张表之间建立连接,从而保证数据的一致性和完整性。
基本格式:
1 | CREATE TABLE 表名( |
1 | ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY(外键字段名) REFERENCES 主表(主表列名); |
例:将worker表和depart表进行连接,外键名字为fk_worker_depart_部门编号。
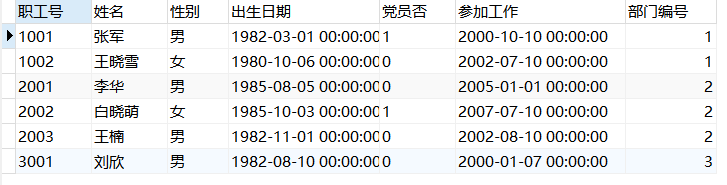

1 | ALTER TABLE worker ADD CONSTRAINT fk_worker_depart_部门编号 FOREIGN KEY (部门编号) REFERENCES depart (部门编号); |
结果展示:

删除外键
基本格式:
1 | ALTER TABLE 表名 DROP FOREIGN KEY 外键名称; |
例:删除外键fk_worker_depart_部门编号。
1 | ALTER TABLE worker DROP FOREIGN KEY fk_worker_depart_部门编号; |
结果展示:

删除/更新行为
| 行为 | 说明 |
|---|---|
| NO ACTION | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除/更新。(与RESTRICT一致)。 |
| RESTRICT | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除/更新。(与NO ACTION一致)。 |
| CASCADE | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则也删除/更新外键在子表中的记录。 |
| SET NULL | 当在父表中删除对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为NULL(这就要求该外键允许取NULL)。 |
| SET DEFAULT | 父表有变更时,子表将外键列设置成一个默认的值(lnnodb不支持) |
基本格式:
1 | ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名) ON UPDATE CASCADE ON DELETE CASCADE; |
多表查询
多表关系
项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种。
- 一对多(多对一)
- 多对多
- 一对一
一对多(多对一)
案例:部门与员工的关系。
关系:一个部门对应多个员工,一个员工对应一个部门。
实现:在多的一方建立外键,指向一的一方的主键。
多对多
案例:学生与课程的关系。
关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择。
实现:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键。
多对一
案例:学生与课程的关系。
关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择。
实现:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键。
一对一
案例:用户与用户详情的关系。
关系:一对一关系,多用于单表拆分,将一张表的基础字段放在一张表中,其他详情字段放在另一张表中,以提高操作效率。
实现:在任意一方加入外键,关联另外一方的主键,并设置外键为唯一的(UNIQUE)。
多表查询概述
指从多张表中查询数据。
笛卡尔积:笛卡尔乘积是指在数学中,两个集合A集合和B集合的所有组合情况。(在多表查询时,需要消除无效的笛卡尔积)
现在准备三张表:
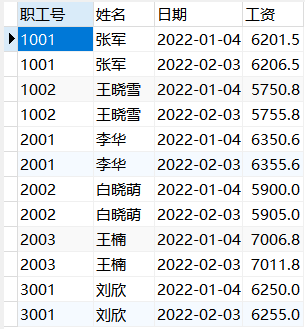
例:直接查询worker表和depart表的所有数据。
1 | SELECT * FROM worker, depart; |
结果展示:

由上图可知,如果直接查询两个表,则会对其就笛卡尔积,数据量为两个表中的数据量相乘,因此我们需要用WHERE过滤掉不需要的笛卡尔积。
多表查询分类
连接查询
内连接:相当于查询
A、B交集部分数据。外连接:
左外连接:查询左表所有数据,以及两张表交集部分数据。
右外连接:查询右表所有数据,以及两张表交集部分数据。
自连接:当前表与自身的链接查询,自连接必须使用表别名。
子查询
内连接
内连接查询的是两张表交集的部分。
隐式内连接
基本格式:
1 | SELECT |
例:查询每一个员工的姓名及关联的部门名称。
1 | USE factory; |
结果展示:
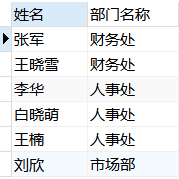
显式内连接
基本格式:
1 | SELECT |
例:查询每一个员工的姓名及关联的部门名称。
1 | USE factory; |
结果展示:
外连接
左外连接和右外连接在数据中有NULL数据时才会有效果,左外连接会完全包含左表的信息,反之,右外连接完全包含右表的信息。
左外连接
1 | SELECT |
相当于查询表1(左表)的所有数据,包含表1和表2交集部分的数据。
右外连接
1 | SELECT |
相当于查询表2(右表)的所有数据,包含表1和表2交集部分的数据。
自连接
把一张表看作两张表,进行连接,表一定要起别名。
基本格式:
1 | SELECT |
注:自连接查询,可以是内连接查询,也可以是外连接查询。
子查询
概念:SQL语句中嵌套SELECT语法,称为嵌套查询,又称子查询。
基本格式:
1 | SELECT |
注:子查询外部的语句可以是INSERT/UPDATE/SELECT的任何一个。
根据子查询结果不同,分为:
- 标量子查询(子查询结果为单个值)
- 列子查询(子查询结果为一列)
- 行子查询(子查询结果为一行)
- 表子查询(子查询结果为多行多列)
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
常用的操作符:= <> > >= < <=
例:查询财务处的所有员工的信息。
1 | USE factory; |
结果展示:

列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用的操作符:IN、NOT IN、ANY、SOME、ALL
| 操作符 | 描述 |
|---|---|
| IN | 在指定的集合范围之内,多选一 |
| NOT IN | 不在指定的集合范围之内 |
| ANY | 子查询返回列表,有任意一个满足即可 |
| SOME | 与ANY等同,使用SOME的地方都可以使用ANY |
| ALL | 子查询返回列表的所有值都必须满足 |
例:查询财务处和人事处的所有员工的信息。
1 | USE factory; |
结果展示:
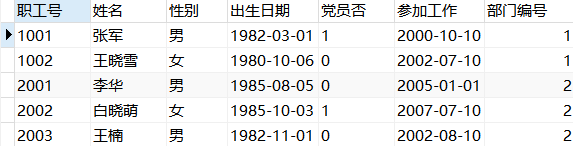
例:查询比财务处所有人工资都高的员工信息。
1 | USE factory; |
结果展示:

行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= <> IN NOT IN
例:查询工号为2001的员工的部门编号和性别都相同的人的员工信息。
1 | USE factory; |
结果展示:

表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。
常用的操作符:IN
例:查询工号为1001或2001的员工的部门编号和性别都相同的人的员工信息。
1 | USE factory; |
结果展示:

视图
介绍
视图(View)是一种虚拟存在的表。视图中的数据并不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的。
通俗的讲,视图只保存了查询的SQL逻辑,不保存查询结果。所以我们在创建视图的时候,主要的工作就落在创建这条SQL查询语句上。
创建
基本格式:
1 | CREATE [ OR REPLACE ] VIEW 视图名称 [(列表名称)] AS SELECT语句 [ WITH [ CASCADED | LOCAL ]] CHECK OPTION; |
例:创建一个视图emp_v_1,存储emp表中id小于等于10的记录的id和name。
1 | USE mydb; |
结果展示:
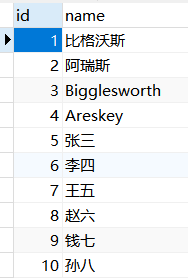
查询
查看创建视图语句
基本格式:
1 | SHOW CREATE VIEW 视图名称; |
例:查询视图emp_v_1的创建语句。
1 | USE mydb; |
结果展示:
1 | CREATE ALGORITHM=UNDEFINED DEFINER=`root`@`localhost` SQL SECURITY DEFINER VIEW `emp_v_1` AS select `emp`.`id` AS `id`,`emp`.`name` AS `name` from `emp` where (`emp`.`id` <= 10) |
查看视图数据
基本格式:
1 | SELECT |
例:查询视图emp_v_1的数据。
1 | USE mydb; |
结果展示:
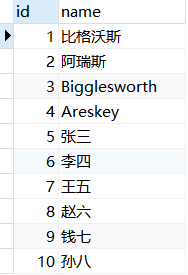
修改视图
基本格式:
1 | CREATE [ OR REPLACE ] VIEW 视图名称 [(列表名称)] AS SELECT语句 [ WITH [ CASCADED | LOCAL ]] CHECK OPTION; |
1 | ALTER VIEW 视图名称 [(列名列表)] AS SELECT语句 [ WITH [ CASCADED | LOCAL ] CHECK OPTION ]; |
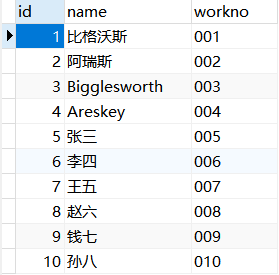
例:修改视图emp_v_1,将其查询结果增加一条workno。
1 | USE mydb; |
结果展示:
删除
基本格式:
1 | DROP VIEW [ IF EXISTS ] 视图名称 [,视图名称]...; |
例:删除视图emp_v_1的数据。
1 | USE mydb; |
结果展示:
1 | DROP VIEW emp_v_1 |
存储过程
介绍
存储过程是事先经过编译并存储在数据库中的一段SQL语句的集合,调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的。
存储过程思想上很简单,就是数据库SQL语言层面的代码封装与重用。*
特点
- 封装,复用
- 可以接收参数,也可以返回数据
- 减少网络交互,效率提升
基本操作
创建
基本格式:
1 | CREATE PROCEDURE 存储过程名称 ([参数列表]) |
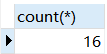
例:创建一个存储过程p1,用来查询emp表中的记录条数。
1 | USE mydb; |
调用
基本格式:
1 | CALL 名称 ([参数]); |
例:调用存储过程p1。
1 | CALL p1; |
结果展示:
查看
查询某个存储过程的定义。
基本格式:
1 | SHOW CREATE PROCEDURE 存储过程名称; |
例:查看存储过程p1的定义。
1 | SHOW CREATE PROCEDURE p1; |
结果展示:
1 | CREATE DEFINER=`root`@`localhost` PROCEDURE `p1`() |
删除
基本格式:
1 | DROP PROCEDURE [ IF EXISTS ] 存储过程名称; |
例:查看存储过程p1的定义。
1 | USE mydb; |
结果展示:
1 | > OK |
变量
系统变量
系统变量是MYSQL服务器提供,不是用户定义的,属于服务器层面。分为全局变量(GLOBAL)、会话变量(SESSION)。
设置系统变量
基本格式:
1 | SET [ SESSION | GLOBAL ] 系统变量名 = 值; |
1 | SET @@[ SESSION | GLOBAL ] 系统变量名 = 值; |
用户定义变量
用户定义变量是用户根据需要自己定义的变量,用户变量不用提前声明,在用的时候直接用@变量名使用就可以。其作用域为当前连接。
用户定义的变量无序对其进行声明或初始化,只不过获取到的值为NULL。
赋值
1 | SET @var_name = expr [, @var_name = expr ]...; |
1 | SELECT |
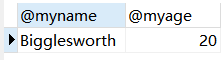
例:定义变量myname和age,其值分别为Bigglesworth和20。
1 | SET @myname = 'Bigglesworth', |
使用
1 | SELECT @var_name |
例:输出上面定义的两个变量。
1 | SELECT |
结果展示:
局部变量
局部变量是根据需要定义的在局部生效的变量,访问之前,需要DECLARE声明。可用作存储过程内的局部变量和输入参数,局部变量的的范围是在其内声明的BEGIN ... END块。
声明
基本格式:
1 | DECLARE 变量名 变量类型 [ DEFAULT...]; |
数据类型就是数据库字段类型:INT、BIGINT、CHAR、VARCHAR、DATE、TIME等。
赋值
基本格式:
1 | SET 变量名 = 值; |
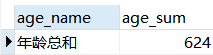
例:定义一个存储过程p,存储emp表格中所有人的年龄之和。
1 | CREATE PROCEDURE p () BEGIN |
结果展示:
if
基本格式:
1 | IF 条件 1 THEN |
例:根据定义的分数score变量,判定当前分数对应的分数等级。
score >= 85分,等级为优秀。score >= 60分 且score < 85分,等级为及格。score < 60分,等级为不及格。
1 | CREATE PROCEDURE score() |
结果展示:
1 | 不及格 |
参数
| 类型 | 含义 | 备注 |
|---|---|---|
| IN | 该类参数作为输入,也就是需要调用时传入值 | 默认 |
| OUT | 该类参数作为输出,也就是该参数可以作为返回值 | |
| INOUT | 既可以作为输入参数,也可以作为输出参数 |
基本格式:
1 | CREATE PROCEDURE 存储过程名称 ([ IN / OUT / INOUT 参数名 参数类型 ]) |
例:根据传入的参数val,判定当前分数对应的分数等级并返回。
score >= 85分,等级为优秀。score >= 60分 且score < 85分,等级为及格。score < 60分,等级为不及格。
1 | CREATE PROCEDURE score(IN val INT, OUT result VARCHAR(10)) |
结果展示:
1 | 及格 |
while
while循环是有条件的循环控制语句。满足条件后,再执行循环体中的SQL语句。
基本格式:
1 | WHILE 条件 DO |
例:计算从1累加到n的值,n为传入的参数值。
1 | CREATE PROCEDURE s(IN n INT, OUT ans INT) |
结果展示:
1 | 55 |
触发器
介绍
触发器是与表有关的数据库对象,指在insert/update/delete之前或之后,触发并执行触发器中定义的SQL语句集合。触发器的这种特性可以协助应用在数据库端确保数据的完整性,日志记录,数据校验等操作。
使用别名OLD和NEW来引用触发器中发生变化的记录内容,这与其他的数据库是相似的。现在触发器还只支持行级触发,不支持语句级触发。
| 触发器类型 | NEW和OLD |
|---|---|
| INSERT型触发器 | NEW表示将要或者已经新增的数据 |
| UPDATE型触发器 | OLD表示修改之前的数据,NEW表示将要或已经修改后的数据 |
| DELETE型触发器 | OLD表示将要或者已经删除的数据 |
触发器基础操作
创建
基本格式:
1 | CREATE TRIGGER trigger_name |
查看
1 | SHOW TRIGGERS; |
删除
1 | DROP TRIGGER [schema_name.]trigger_name; -- 如果没有指定schema_name,默认为当前数据库 |
 微信
微信 支付宝
支付宝







